
정규화란?
데이터베이스의 데이터들을 최대한 중복을 제거하여 이상 현상 ( Anomaly ) 을 방지하기 위한 기술이다.
여기서 말하는 이상현상은 세 가지가 있는데 간략하게 설명하면 다음과 같다.
갱신 이상 ( Modification Anomaly )
중복된 데이터 중 일부를 갱신할 때 의도치 않은 데이터가 갱신됨으로써 생기는 데이터의 불일치
삽입 이상 ( Insertion Anomaly )
새 데이터를 삽입할 때 의도치 않은 데이터가 삽입됨으로써 생기는 데이터의 불일치
삭제 이상 ( Deletion Anomaly )
데이터를 삭제할 때 의도치 않은 데이터까지 삭제됨으로써 생기는 데이터의 불일치
이러한 이상 현상을 해결하기위해 데이터를 잘게 잘게 쪼개나간다고 생각하면 쉽다.
이 정규화는 단계별로 나누어지는데 각 단계별로 알아보자.
제 1정규화
먼저 아래와 같은 학생 테이블이 있다고 가정해보자
[ 학생 ] 테이블
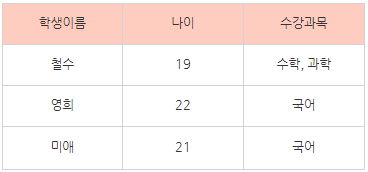
현재 테이블은 속성 하나는 하나의 속성값만을 가져야 한다는 1차 정규형에 위배된다.
수강과목컬럼을 보면 철수가 수학과 과학의 속성값 두 개를 가지고 있음을 알 수 있다.
이를 쪼개주는 것을 원자값을 갖는다고 하며 이것이 제 1정규화이다.
제 1정규화를 거치면 아래와 같다.
[ 학생 ] 테이블

제 2정규화
방금 제 1정규화를 거친 테이블을 보면
중복데이터로 인해 학생이름으로 ROW를 구분할 수 없고 나이 또한 ROW를 구분할 수 없다.
학생이름과 수강과목 두 가지를 합친 [ 학생이름, 수강과목 ] 기본키로만 각 ROW를 구분할 수 있다.
이는 다르게 말해 학생이름과 수강과목을 알면 나이를 알 수 있다는 말이 되기도 하는데
여기서 문제가 나이는 학생이름에 종속되어져 있기에 학생이름 하나만 알더라도 나이를 알 수 있다는 것이다.
이렇게 기본키 중에 특정 컬럼에만 종속된 컬럼이 존재할 경우 2차 정규형에 위배된다.
이를 해결하기 위해 제 2정규화를 실행하며 제 2정규화를 거치면 아래와 같다.
[ 학생 ] 테이블

[ 과목 ] 테이블

이렇게 제 1정규화와 제 2정규화를 알아보았다.
제 3정규화
다음으로 제 3정규화는 제 2정규형을 만족하는 상태에서 이행 함수 종속을 제거하는 정규화 과정을 말한다.
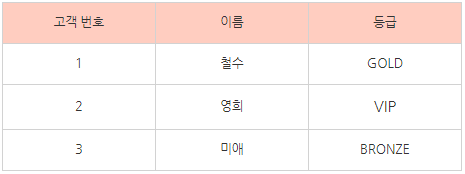
아래와 같이 어느 한 통신사의 고객 정보 테이블이 있다고 가정하자.
[ 고객정보 ] 테이블

여기서 고객 번호를 알면 각 컬럼의 속성 값들을 찾아낼 수 있다. 그런데 자세히 보면 등급은 고객 번호에 의해 결정되어지고
할인율은 등급에 의해 결정되어진다. 이는 논리적으로 보면 할인율은 고객 번호에 의해 결정되어지는 아이러니한 모습을 나타내는 셈이다.
이 상황처럼 X->Y, Y->Z 일 때 X->Z 를 만족해버리면 이행 함수 종속이 발생한다고 한다. 이를 제거하는 것이 제 3정규화.
제 3정규화를 거치면 다음과 같이 테이블을 나타낼 수 있다.
[ 등급 ] 테이블

[ 고객정보 ] 테이블
이렇게 하면 제 2정규형을 만족하면서 이행 함수 종속을 제거한 제 3정규형의 상태가 되는 것이다.
정규화는 데이터베이스를 사용하는데 있어 필수불가결한 요소이다.
제대로 숙지해 좀 더 이쁘고 말랑말랑한 데이터베이스를 만들어보도록 하자.
'Coding Story > DATABASE' 카테고리의 다른 글
| [ Oracle ] 오라클 중복데이터 처리, 중복데이터 한번만 (0) | 2020.10.28 |
|---|---|
| [ Oracle ] 프로시저와 함수의 차이 (7) | 2020.10.28 |
| [ Database ] ER 다이어그램 / ERD 기호 및 표기법 (8) | 2020.10.28 |
| [ Database ] IE 표기법과 BARKER 표기법 ( 참고용 ) (0) | 2020.10.28 |
| [ MySQL ] 문자열 사이에 구분자 넣어 조회하기 (0) | 2020.03.04 |
